Introduction: What Is Spark?
Introduction: What Is Spark?
Let's start with an overview of Spark.
Apache Spark is a distributed computing system written in Scala for distributed data programming.
Spark includes support for event stream processing, as well as more traditional batch-mode applications. There is a SparkSQL module for working with data sets through SQL queries. It integrates the core Spark API with embedded SQL queries with defined schemas. It also offers Hive integration so you can query existing Hive tables, even create and delete them. Finally, it has JSON support, where records written in JSON can be parsed automatically with the schema inferred and RDDs can be written as JSON.
There is also an interactive shell, which is an enhanced version of the Scala REPL (read, eval, print loop shell). SparkSQL adds a SQL-only REPL shell. For completeness, you can also use a custom Python shell that exposes Spark's Python API. A Java API is also supported and R support is under development.
Why Spark?
By 2013, it became increasingly clear that a successor was needed for the venerable Hadoop MapReduce compute engine. MapReduce applications are difficult to write, but more importantly, MapReduce has significant performance limitations and it can't support event-streaming ("real-time") scenarios.
Spark was seen as the best, general-purpose alternative, so all the major Hadoop vendors announced support for it in their distributions.
Spark Clusters
Let's briefly discuss the anatomy of a Spark cluster, adapting this discussion (and diagram) from the Spark documentation. Consider the following diagram:
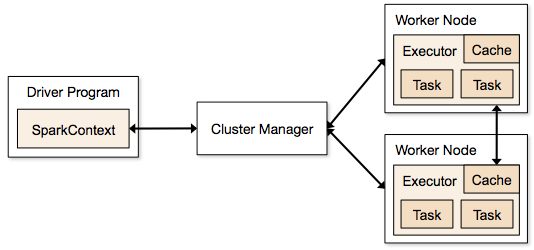
Each program we'll write is a Driver Program. It uses a SparkContext to communicate with the Cluster Manager, which is an abstraction over Hadoop YARN, local mode, standalone (static cluster) mode, Mesos, and EC2.
The Cluster Manager allocates resources. An Executor JVM process is created on each worker node per client application. It manages local resources, such as the cache (see below) and it runs tasks, which are provided by your program in the form of Java jar files or Python scripts.
Because each application has its own executor process per node, applications can't share data through the Spark Context. External storage has to be used (e.g., the file system, a database, a message queue, etc.)
Resilient, Distributed Datasets
The data caching is one of the key reasons that Spark's performance is considerably better than the performance of MapReduce. Spark stores the data for the job in Resilient, Distributed Datasets (RDDs), where a logical data set is virtualized over the cluster.
The user can specify that data in an RDD should be cached in memory for subsequent reuse. In contrast, MapReduce has no such mechanism, so a complex job requiring a sequence of MapReduce jobs will be penalized by a complete flush to disk of intermediate data, followed by a subsequent reloading into memory by the next job.
RDDs support common data operations, such as map, flatmap, filter, fold/reduce, and groupby. RDDs are resilient in the sense that if a "partition" of data is lost on one node, it can be reconstructed from the original source without having to start the whole job over again.
The architecture of RDDs is described in the research paper Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing.
RDDs architecture
Now given a dummy error log, let us try to decode Spark internal procedures:
example.log
ERROR mesos: going crazy
WARN david, are you angry at me?
ERROR did hdfs just crashed again our VMs?
WARN iris is approaching
ERROR mesos cluster: replace with spark cluster
A example Apache Spark program would look like this
// load error messages from a log into memory
// then interactively search for various patterns
// base RDD
val lines = sc.textFile("hdfs://log.txt")
// transformed RDDs
val errors = lines.filter(_.startsWith("ERROR"))
val messages = errors.map(_.split("\t")).map(r => r(1))
messages.cache()
// actions
messages.filter(_.contains("mesos")).count()
messages.filter(_.contains("hdfs")).count()
Lets have a look at the transformed RDD operator graph (I will go into detail about RDDs later thus they are the secret to Spark's Performance)
scala> messages.toDebugString
res1: String =
MappedRDD[4] at map at <console>:16 (3 partitions)
MappedRDD[3] at map at <console>:16 (3 partitions)
FilteredRDD[2] at filter at <console>:14 (3 partitions)
MappedRDD[2] at textFile at <console>:12 (3 partitions)
HadoopRDD[0] at textFile at <console>:12 (3 partitions)
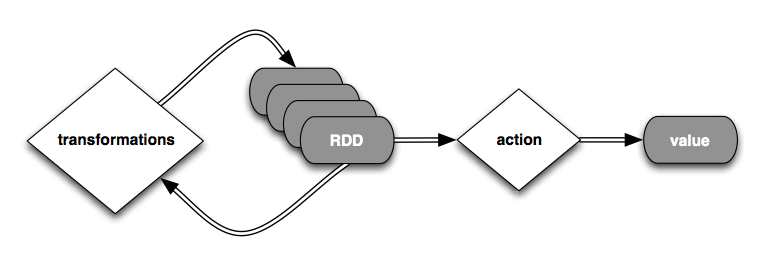
What actually happens is, that
- Spark creates a base Resilient Distributed Dataset (RDD) in the first line called lines
- Spark transforms the base RDD by filtering for 'ERROR' and splitting up the words. Note: Every transformation is remembered (like in a git push). Therefore lost data can be easily recreated!
- Spark then saves the RDD in an cache for faster processing
- Spark preforms an action to extract value from the RDD and reports it to the Driver
The Spark Version and further readings
We are referring to Spark 1.1.0
The following documentation links provide more information about Spark:
The Documentation includes a getting-started guide and overviews. You'll find the Scaladocs API.